
Rust 从 0 到 1 (生命周期、返回值、错误处理)
Rust 从 0 到 1 (生命周期、返回值、错误处理)
生命周期是 Rust 特有的,在 Rust 中函数和变量有其作用域,在一个函数中可以嵌套作用域,如:
1 | fn main(){ |
对于生命周期其实就是引用的有效作用域,大多数情况下无需手动声明生命周期,编辑器可以进行自动推导,当然也有无法推导的情况
悬垂指针和生命周期
生命周期的主要作用是避免悬垂引用,它会导致程序引用了不该引用的数据,如:
1 | { |
在这里首先是 let r 没有初始化,在其次是 r 引用了内部作用域的 x 变量,但是 x 变量在内部作用域结束时已经释放掉了,最后 r 会引用一个无效的 x,导致 r 变成了一个悬垂指针。
借用检查
为了保证所有权和借用的正确性,Rust 会使用借用检查器(Borrow checker)来检查程序的借用正确性。如:
1 | { |
在这里,r的生命周期为'a, x 的生命周期为 'b ,从图示上可以看出生命周期 'b 比 'a 小的多。在编译期 Rust 会检查变量的生命周期,上面的代码中 r 的生命周期引用了一个小的多生命周期 x,这个时候编译器就认为程序存在风险,则会抛出异常。
想通过编译就需要让生命周期 'b比 'a 大,也就是 x 变量要比 r 活得久,对代码进行如下修改:
1 | { |
现在 x 的生命周期比 r 的生命周期大,因此 r 对 x 的引用是安全的。
生命周期标注语法
在 Rust 中以 '开头,名称为一个单独的小写字母,大部分多数使用'a 来作为生命周期的名称, 如果是引用类型的参数,那么生命周期会位于引用符号 & 之后,并用一个空格来将生命周期和引用参数分隔开。如:
1 | &i32 // 一个引用 |
生命周期的标注主要作用是告诉编译器多个引用之间的关系,没有什么其他的意义。
需要注意的是:生命周期标注并不会改变任何引用的实际作用域
函数签名中的生命周期标注
需要比较两个字符串切片中返回较长的字符串切片:
1 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { |
注意:
- 使用生命周期参数需要先声明
<'a> x,y和返回值至少活的和'a一样久
longest 函数签名表明对于生命周期 'a,其两个参数和函数具有相同的生命周期,返回值也具有相同的生命周期。但是实际上,返回值的生命周期适合参数中的生命周期中的最小值一致的。
总结:在通过函数签名指定生命周期参数时,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件时,就拒绝编译通过。
来看个例子:
1 | fn main() { |
首先 string1 的生命周期是跟随 main 函数一起结束的,而 string2是跟随内部作用域一起结束的。由于 'a 是两者中的最小作用域,也就是说 'a 的生命周期是等于 string2 的生命周期的,由于函数返回值的生命周期也是 'a 因此函数返回值的生命周期也等于 string2 的生命周期。
如果函数如下:
1 | fn main() { |
在编译时就会出现一个错误: string2 does not live long enough
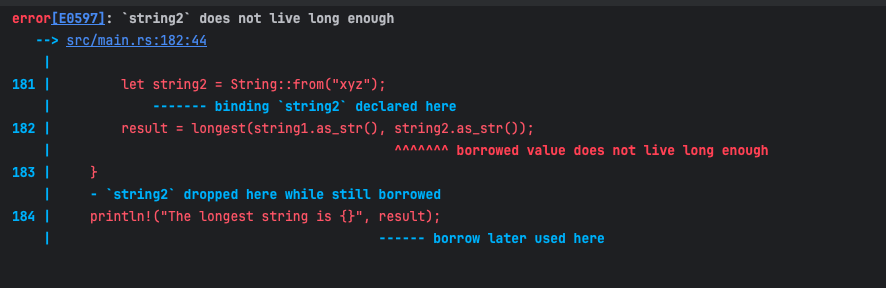
在上面的代码中 string2 的生命周期是 'a, 但实际上 string2在内部作用域结束后就释放了,因此它的生命周期是小于 'a的,在编译时就会报错。
使用生命周期的方式取决于函数的功能,如果现在有一个函数它永远只返回第一个参数,那么它的生命周期的标注如下:
1 | fn longest<'a>(x: &'a str, y: &str) -> &'a str { |
在这里 y 并没有被使用,因此 y 的生命周期和返回值的生命周期没有关系,所以我们可以不用标注 y 的生命周期。
函数的返回值如果是一个引用类型,那么它的生命周期只会来源于:
- 函数参数的生命周期
- 函数体中某个新建引用的生命周期(悬垂引用)
结构体中的生命周期
之前的结构都是使用非引用类型字段上,当有了生命周期之后在结构体中使用引用也是可能的:只要为结构体中的每一个引用标注生命周期即可。如:
1 | struct ImportantExcerpt<'a> { |
结构体 ImportantExcerpt 中有一个引用类型的字段 part,因此需要标注上生命周期。需要注意的是:结构体 ImportantExcerpt 所引用的字符串 str 生命周期需要大于等于该结构体的生命周期。若是将代码改成:
1 | #[derive(Debug)] |
则无法通过编译因为结构体所引用的字符串的生命周期小于结构体的生命周期。
生命周期消除
对于 Rust 编译器来说,每一个引用类型都有一个生命周期。但是为了简化用户的使用,运用了生命周期消除大法。在了解消除规则之前需要注意以下几个问题:
- 消除规则不是万能的,若编译器不能确定某件事是正确时,会直接判为不正确,那么你还是需要手动标注生命周期
- 函数或者方法中,参数的生命周期被称为
输入生命周期,返回值的生命周期被称为输出生命周期
三条消除规则
每一个引用参数都会获得独自的生命周期
1
2
3
4// 一个引用参数就有一个生命周期标注
fn foo<'a>(x: &'a i32)
// 两个引用参数就有两个生命周期标注
fn foo<'a, 'b>(x: &'a i32, y: &'b i32)若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期
1
2
3fn foo(x: &i32) -> &i32
// x 的生命周期会被自动赋给返回值,那么该函数等同于
fn foo<'a>(x: &'a i32) -> &'a i32若存在多个输入生命周期,且其中一个是 &self 或 &mut self,则 &self 的生命周期被赋给所有的输出生命周期
方法中的生命周期
为具有生命周期的结构体实现方法时,使用方法如下:
1 | struct ImportantExcerpt<'a> { |
该语法跟范型参数语法相似。但是有几点需要注意:
impl中必须使用结构体的完整名称,包括<'a>,因为生命周期标注也是结构体类型的一部分- 方法签名中,往往不需要标注生命周期,得益于生命周期消除的第一和第三规则
第三规则应用的场景例子:
1 | impl<'a> ImportantExcerpt<'a> { |
根据三条消除规则,该函数等效于
1 | impl<'a: 'b, 'b> ImportantExcerpt<'a> { |
在这里需要注意的是:
'a: 'b,是生命周期约束语法,跟泛型约束非常相似,用于说明'a必须比'b活得久- 可以把 ‘a 和 ‘b 都在同一个地方声明(如上),或者分开声明但通过 where ‘a: ‘b 约束生命周期关系,如:
1
2
3
4
5
6
7
8
9impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'b str
where
'a: 'b,
{
println!("Attention please: {}", announcement);
self.part
}
}
静态生命周期
在 Rust 中有一个非常特殊的生命周期,那就是 ‘static,拥有该生命周期的引用可以和整个程序的生命周期一样,如字符串字面量和特征对象。
1 | let s: &'static str = "Hello,World!"; |
错误处理
在 Rust 中错误处理主要分为两类:
- 可恢复错误,通常用于从系统全局角度来看可以接受的错误,例如处理用户的访问、操作等错误,这些错误只会影响某个用户自身的操作进程,而不会对系统的全局稳定性产生影响
- 不可恢复错误,刚好相反,该错误通常是全局性或者系统性的错误,例如数组越界访问,系统启动时发生了影响启动流程的错误等等,这些错误的影响往往对于系统来说是致命的
在 Rust 中使用 Result<T, E> 用于可恢复错误,panic! 用于不可恢复错误.
panic! 于不可恢复错误
触发 panic! 主要有两种方式
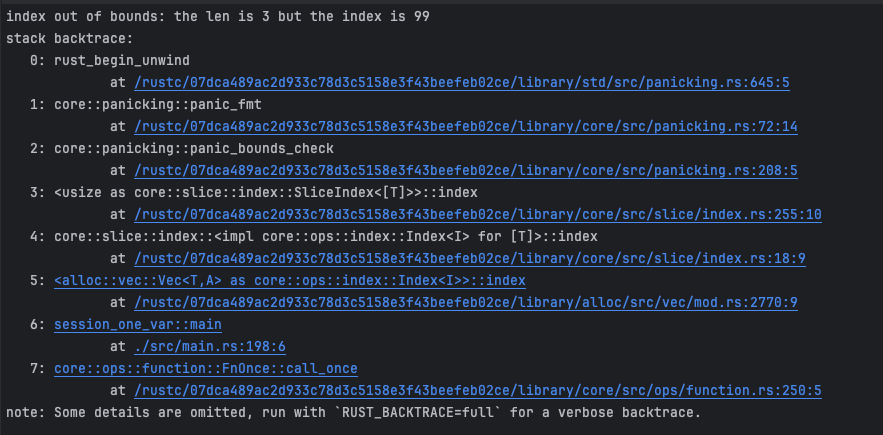
被动触发
如数组访问越界:
1 | fn main() { |
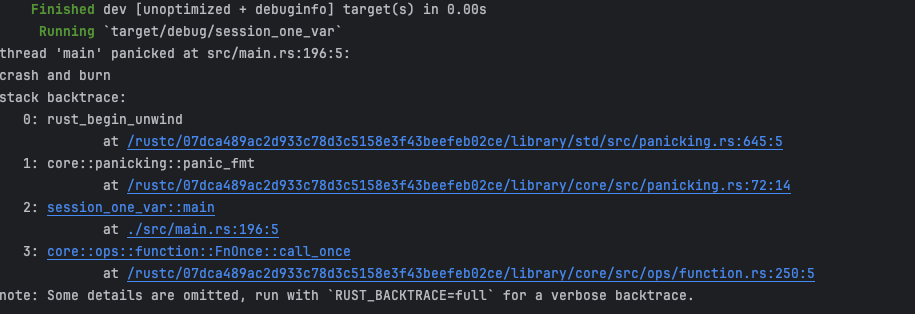
主动调用
在某些特殊情况下需要主动抛出错误,如在读取文件的过程中读取文件失败。Rust 为我们提供了 panic! 宏,当调用执行该宏时,程序会打印出一个错误信息,展开报错点往前的函数调用堆栈,最后退出程序。如:
1 | fn main() { |
panic 的两种种植方式
当程序出现 panic 时,会提供两种方式来终止流程:栈展开和直接终止。
默认的方式就是 栈展开,Rust 会回溯栈上数据和函数调用,好处是可以给出充分的报错信息和栈调用信息,便于事后的问题复盘。
直接终止,不清理数据就直接退出程序,善后工作交与操作系统来负责。
如果 panic 发生在主线程中程序终止推出,如果发生在子线程中则该线程终止,但不会影响主线程。因此尽量不要在主线程中做太多任务,将任务将给子线程去做。
panic 使用的主要场景如下:
- 示例、原型、测试
- 可能导致全局有害状态时
有害状态大概分为几类:
- 非预期的错误
- 后续代码的运行会受到显著影响
- 内存安全的问题
可恢复错误 Result
Result<T, E> 是一个枚举类型,它的定义如下:
1 | enum Result<T, E> { |
泛型参数 T 代表成功时存入的正确值的类型,存放方式是 Ok(T),
泛型参数 E 代表错误时存入的错误值,存放方式是 Err(E)。
Result 的使用方式如下:
1 | use std::fs::File; |
,如果是成功,则将 Ok(file) 中存放的的文件句柄 file 赋值给 f,如果失败,则将 Err(error) 中存放的错误信息 error 使用 panic 抛出来,进而结束程序。
对返回的错误进行处理
我们可以对部分错误进行处理,而不是所有的错误都直接崩溃退出:
1 | use std::fs::File; |
在这里如果是文件不存在错误 ErrorKind::NotFound,就创建文件,File::create 同样返回 Result 再通过 match 对错误进行匹配,如果创建失败则 panic。其他的错误直接 panic
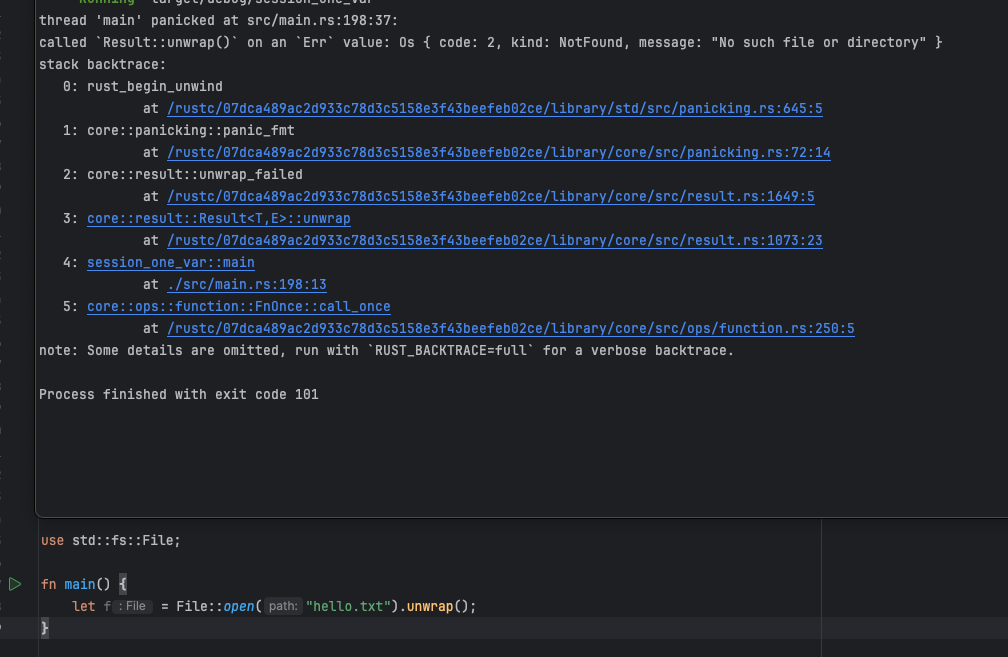
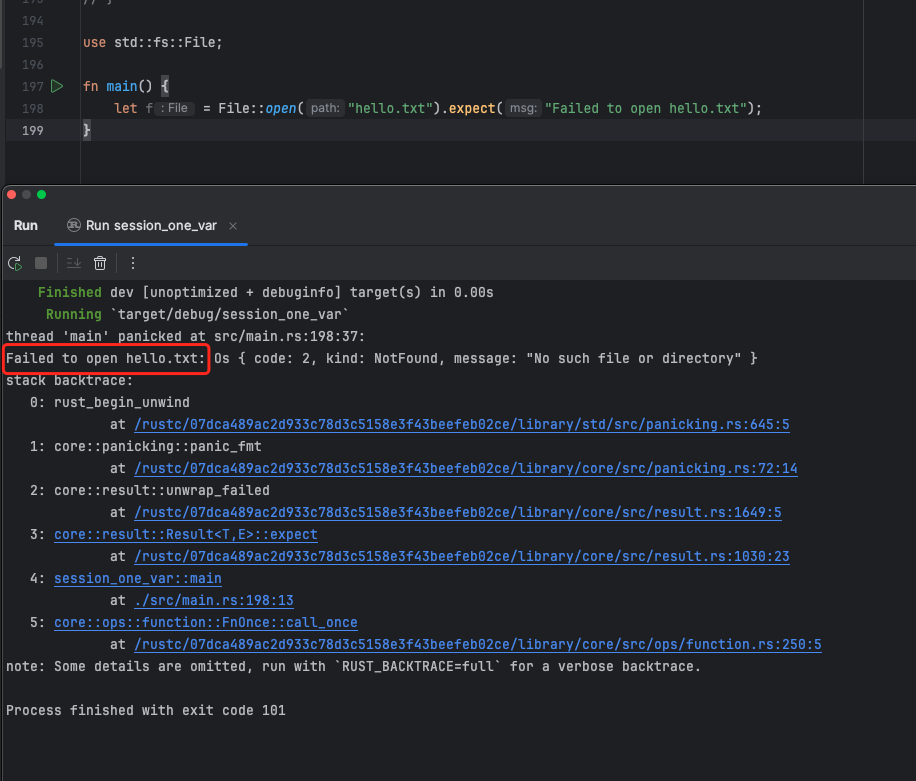
unwrap 和 expect
首先是 unwrap,在遇到错误时会直接 panic,效果如下:
而 expect 会打印自定义的错误信息。
错误传播
在实际应用中,会把错误层层上传然后交给调用链上游函数进行处理,错误传播将非常常见。如函数从文件中读取用户名,然后将结果进行返回:
1 | use std::fs::File; |
该函数返回一个 Result<String, io::Error> 类型,当读取用户名成功时,返回 Ok(String),失败时,返回 Err(io:Error); File::open 和 f.read_to_string 返回的 Result<T, E> 中的 E 就是 io::Error。
上面的写法过于麻烦,好在 Rust 提供 ? 可以简化上面的代码:
1 | use std::fs::File; |
其实 ? 就是一个宏,它的作用跟上面的 match 几乎一模一样。? 有一个比 match 好用的特性那就是自动类型转换,得益于标准库中定义的 From 特征,该特征有一个方法 from,用于把一个类型转成另外一个类型,? 可以自动调用该方法,然后进行隐式类型转换。因此只要函数返回的错误 ReturnError 实现了 From<OtherError> 特征,那么 ? 就会自动把 OtherError 转换为 ReturnError。
这种转换意味着你可以用一个大而全的 ReturnError 来覆盖所有错误类型,只需要为各种子错误类型实现这种转换即可。如:
1 | use std::fs::File; |
? 不仅返回 Result 的 Err还可以返回 Option 的 None,如:
1 | fn first(arr: &[i32]) -> Option<&i32> { |
arr.get 返回一个 Option<&i32> 类型,因为 ? 的使用,如果 get 的结果是 None,则直接返回 None,如果是 Some(&i32),则把里面的值赋给 v。