
Rust 从 0 到 1 (泛型和特征、集合类型)
Rust 从 0 到 1 (泛型和特征、集合类型)
泛型
在我们的编程生涯中,经常遇到同一功能的函数处理不同的类型数据,如整合的加法、浮点数的加法等,在不支持泛型的语言中你需要:
1 | fn add_i8(a:i8, b:i8) -> i8 { |
在编程的时候,我们经常利用多态。通俗的讲,多态就是好比坦克的炮管,既可以发射普通弹药,也可以发射制导炮弹(导弹),也可以发射贫铀穿甲弹,甚至发射子母弹,没有必要为每一种炮弹都在坦克上分别安装一个专用炮管,即使生产商愿意,炮手也不愿意,累死人啊。所以在编程开发中,我们也需要这样“通用的炮管”,这个“通用的炮管”就是多态。
因此呢,泛型就是一种多态。泛型主要是为了减少代码量,避免程序臃肿,同时也可以丰富语言本身的表达能力。在 Rust 中泛型的声明如下:
1 | fn add<T>(list: &[T]) -> T { |
在上面的代码中 T 就是泛型参数,虽然在 Rust 中泛型参数的名称可以任意取名,但惯例使用 T (T 是 type 的首字母)。名称越短越好,一个字母是最完美的。如何使用泛型来编写上面的 add 函数呢?如下:
1 | fn add<T: std::ops::Add<Output = T>>(x: T, y: T) -> T { |
运行结果:T: std::ops::Add<Output = T> 是对参数的约束,暂且不表。
结构体中使用泛型
在 Rust 中结构体中的字段类型也是可以用泛型来定的,如:
1 | struct Point<T> { |
需要注意的是:
- 提前声明,我们在使用泛型参数之前必需要进行声明 Point
,才可以在结构体的字段类型中使用 T 来替代具体的类型 - x 和 y 是相同的类型
类型不同则会报错
枚举中使用泛型
Option 枚举是一个拥有泛型参数 T 的枚举类型,其定义为:
1 | enum Option<T> { |
Some(T),存放了一个类型为 T 的值,因为泛型的存在我们可以在任意一个有返回值的函数中使用 Option<T> 作为返回值,返回的可能是 Some(T) 也可能是 None。 在 Rust 中还有一个枚举 Result,其定义为:
1 | enum Result<T, E> { |
如果函数正常运行,则最后返回一个 Ok(T),T 是函数具体的返回值类型,如果函数异常运行,则返回一个 Err(E),E 是错误类型。例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File),因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error),E 对应的就是 std::io::Error 类型。
方法中使用泛型
方法中也是可以使用泛型的,如:
1 | struct Point<T> { |
使用泛型参数前,依然需要提前声明:impl
还可以为具体的范型类型实现方法,如:
1 | impl Point<f32> { |
Point
const 泛型
在 Rust 1.51 版本引入了 const 泛型,如:
1 | fn display_array(arr: [i32; 3]) { |
其运行结果如下:
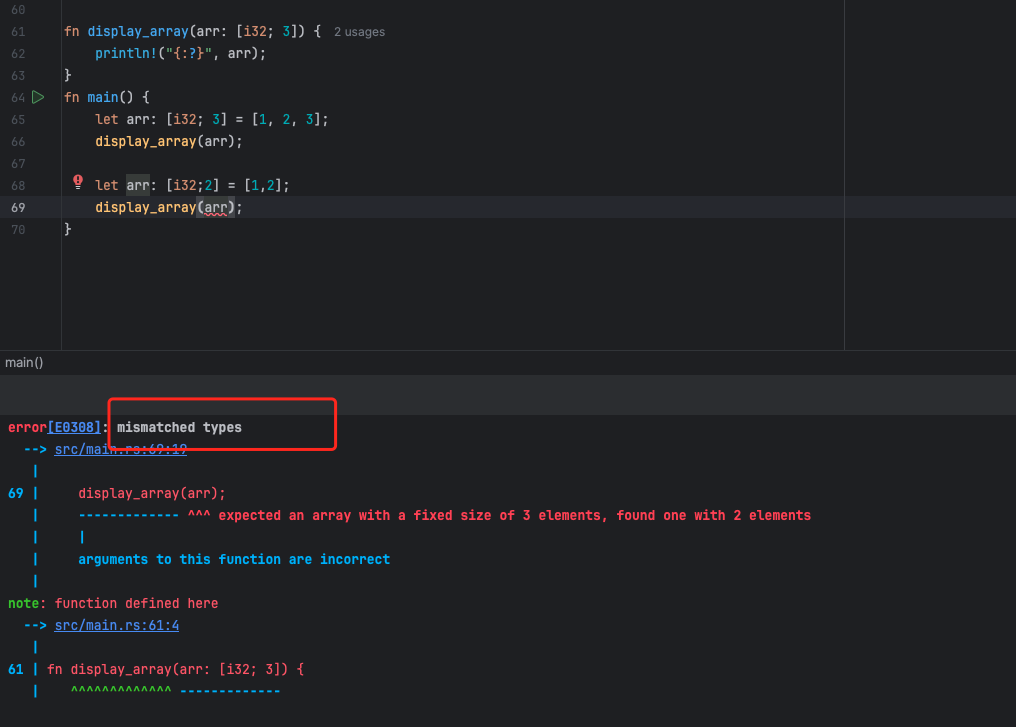
在 Rust 看来,[i32; 3] 和 [i32; 2] 是两种不同的类型,因此不能完成调用,为了能顺利运行,我们修改代码如下:
1 | fn display_array(arr: &[i32]) { |
将参数改为切片即可,为了适配所有的类型,可讲代码改为如下:
1 | fn display_array<T: std::fmt::Debug>(arr: &[T]) { |
这里加上 std::fmt::Debug 是为了 println!("{:?}", arr) 能正常工作。
以前 Rust 的一些数组库,在使用的时候都限定长度不超过 32 ,因此需要为每个长度单独实现一个方法,代码极其臃肿,现在 const 泛型即可解决这个问题:
1 | fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) { |
在这里定义了一个类型为 [T; N] 的数组,其中 T 是一个基于类型的泛型参数,这个和之前讲的泛型没有区别,而重点在于 N 这个泛型参数,它是一个基于值的泛型参数!因为它用来替代的是数组的长度。N 就是 const 泛型,定义的语法是 const N: usize,表示 const 泛型 N ,它基于的值类型是 usize。
特征
特征,其实就是其他语言中的接口,具体来说就是不同类型具有相同的行为,我们就可以定义一个特征,然后实现这个这个特征。定义特征是把一些方法组合在一起,目的是定义一个实现某些目标所必需的行为的集合。
如:我们在发文的时候,可以发自己的 Blog 也可以发其他的媒体上面,在我们需要对文章进行总结的时候,总结这个行为是共享的,那么就可以使用特质来实现:
1 | pub trait Summary { |
代码解释:pub 表示公开的特征,使用 trait 关键字声明一个特征,Summary 是特征名,在大括号中定义该特征的所有方法,如 fn summarize(&self) -> String;。
为类型实现特征
在这里我们以为自己的 Blog 和 Weibo 为例子,看看特征的实现:
1 | pub trait Summary{ |
实现特征的语法与为结构体、枚举实现方法很像:impl Summary for Post,读作“为 Post 类型实现 Summary 特征”,然后在 impl 的花括号中实现该特征的具体方法。
孤儿规则
在 Rust 中特征有一条特别重要的规则: 如果我们要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的。如:在当前作用域下,我们可以是 Blog 实现 Display 特征,也可以使用 String 实现 Summary 特征,但是你不能在当前作用域为 String 实现 Display 特征,好比你用前朝的剑斩本朝的官,那是不可行的,这条规则就是孤儿规则。
默认实现
特征可以有默认的实现,也可以选择重载该方法:
1 | pub trait Summary { |
其运行结果:

默认实现允许调用相同特征中的其他方法,哪怕这些方法没有默认实现。 如:
1 | pub trait Summary { |
weibo.summarize() 会先调用 Summary 特征默认实现的 summarize 方法,通过该方法进而调用 Weibo 为 Summary 实现的 summarize_author 方法,最终输出:1 new weibo: (Read more from @horse_ebooks…)。
约束特征
首先我们看定义:
1 | pub fn notify<T: Summary>(item: &T) { |
T: Summary 被称为特征约束。
如果我们需要强制函数的参数是同一个类型,可以使用特质约束来实现:
1 | pub fn notify<T: Summary>(item1: &T, item2: &T) {} |
泛型类型 T 说明了 item1 和 item2 必须拥有同样的类型,同时 T: Summary 说明了 T 必须实现 Summary 特征。
多重约束
我们还可以指定多个约束条件,如:
1 | pub fn notify(item: &(impl Summary + Display)) {} |
还可以是:
1 | pub fn notify<T: Summary + Display>(item: &T) {} |
Where 约束
当特征约束变得很多时,函数的签名将变得很复杂:
1 | fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {} |
虽然不是很复杂但是还可以简化,使用 where 关键字进行简化:
1 | fn some_function<T, U>(t: &T, u: &U) -> i32 |
函数返回中的 impl Trait
可以通过 impl Trait 来说明一个函数返回了一个类型,该类型实现了某个特征:
1 | fn returns_summarizable() -> impl Summary { |
但是这种返回值方式有一个很大的限制:只能有一个具体的类型。如果返回不同的类型,编译器就会报错。
其他获取特征的方法
- 通过 derive 派生特征,如
#[derive(Debug)], Debug 有一套自动实现的默认代码,当你给一个结构体标记后,就可以使用 println!(“{:?}”, s) 的形式打印该结构体的对象。 - 调用方法需要引入特征,如:
use std::convert::TryInto;。 如果你要使用一个特征的方法,那么你需要将该特征引入当前的作用域中, 如:try_into就需要引入std::convert::TryInto特征。
实际应用
给定一个数组,需要找出其中的最大值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23fn largest<T: PartialOrd + Copy>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
代码解释:PartialOrd 位于 prelude,因此使用的时候不需要手动导入,它要求可以比较的类型,Copy 是要求比较的类型要实现了 Copy 特性,这样才能将所有权转移,如果不加 Copy 则会报错:cannot move out of type [T], a non-copy slice,Copy 特征还是可以使用 Clone 特征,最后运行的结果如下:

特征对象
由于 impl Trait 的返回值类型不支持多种不同类型返回,所以 Rust 引入了特征对象。特征对象,简单理解就是把实现了某一个特征的类型的实例,存储在数组中,在调用时通过调度找到具体的类型方法。可以通过 & 引用或者 Box
1 | // 定义 Draw 特征 |
有几点注意:
- draw1 函数的参数是 Box
形式的特征对象,该特征对象是通过 Box::new(x) 的方式创建的 - draw2 函数的参数是 &dyn Draw 形式的特征对象,该特征对象是通过 &x 的方式创建的
- dyn 关键字只用在特征对象的类型声明上,在创建时无需使用 dyn
可以使用特征对象来代表泛型或具体的类型
特征对象的动态分发
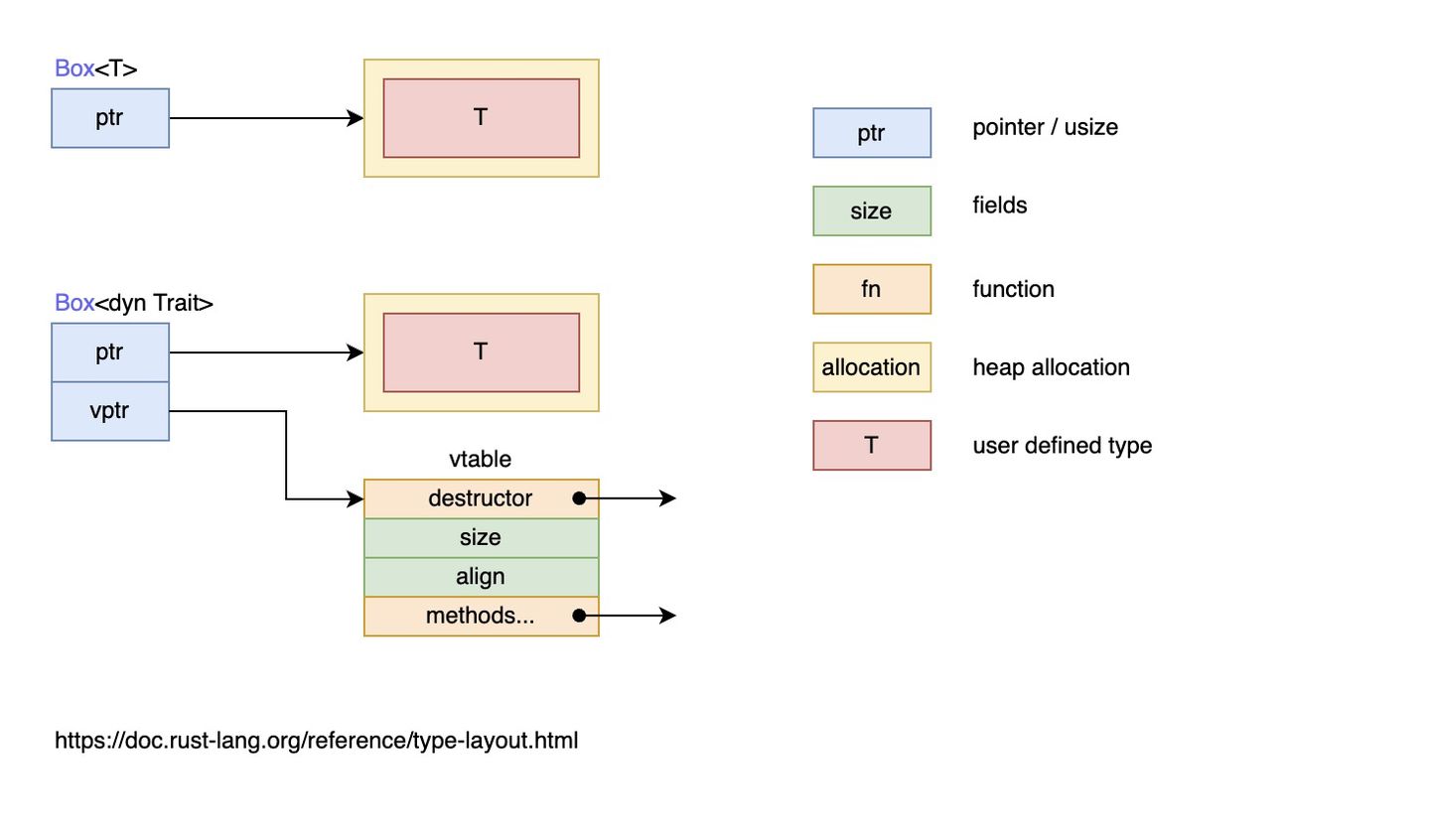
编译器会在编译期为每一个泛型参数对应的具体类型生成一份儿代码,这中分发方式称为静态分发。而动态分发是在运行时才能确定需要调用什么方法的,因此关键字 dyn 强调的就是动态。
当使用特征对象时,Rust 必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法。动态分发也阻止编译器有选择的内联方法代码,这会相应的禁用一些优化。
具体可以看这个图:
Self 与 self
有两个self, self 一个指代当前的实例对象,Self 一个指代特征或者方法类型的别名,如:
1 | trait Draw { |
在这里,self 指代的是当前的实例对象,也就是 button 实例,而 Self 指的是 Button 类型。
特征对象的限制
- 方法的返回类型不能是 Self
- 方法没有任何泛型参数
集合类型
集合在 Rust 中是一类比较特殊的类型,因为 Rust 中大多数数据类型都只能代表一个特定的值,但是集合却可以代表一大堆值。而且与语言级别的数组、字符串类型不同,标准库里的这些家伙是分配在堆上,因此都可以进行动态的增加和减少。在标准库中最常用的集合类型就是:Vector,HashMap 以及 String。
动态数组
动态数组类型用 Vec
创建动态数组
创建动态数组有两种方式,方式一:
1 | // 使用 Vec::new 创建动态数组是最 rusty 的方式 |
方式二:
1 | // 使用宏 vec! 来创建数组,在这里无需标注数据类型,编译器会自动推倒出 v 的类型。 |
更新
向数组尾部添加元素,可以使用 push 方法:
1 | let mut v = Vec::new(); |
注意:声明为 mut 后,才能进行修改。Vector 类型在超出作用域范围后,会被自动删除,其中的元素也会被删除
读取
1 | let v = vec![1, 2, 3, 4, 5]; |
Vector 有两种获取元素的方式:下标和get,二者的区别在下标在越界访问时会退出,而 get 则不会。
一些常用的方法
| 方法 | 说明 |
|---|---|
| new() | 创建一个空的向量的实例 |
| push() | 将某个值 T 添加到向量的末尾 |
| remove() | 删除并返回指定的下标元素 |
| contains() | 判断向量是否包含某个值 |
| len() | 返回向量中的元素个数 |
遍历数组
用下标的方式去遍历数组更安全也更高效,每次下标访问都会触发数组边界检查。
1 | let v = vec![1, 2, 3]; |
遍历时修改元素
1 | let mut v = vec![1, 2, 3]; |
存储不同类型的元素
由于 Vector 只能存储同类型的元素,但是可以使用枚举和特征对象实现存储不同类型的目的,首先是枚举类型:
1 | #[derive(Debug)] |
再特征对象的实现
1 | trait IpAddr { |
同时借用多个数组元素
当遇到借用多个数组元素的情况时需要注意,不能同时存在不可变借用和可变借用,如:
1 | let mut v = vec![1, 2, 3, 4, 5]; |
数组的大小是可变的,当旧数组的大小不够用时,Rust 会重新分配一块更大的内存空间,然后把旧数组拷贝过来。这种情况下,之前的引用显然会指向一块无效的内存。
HashMap
HashMap 也是 Rust 标准库中提供的集合类型,但是又与动态数组不同,HashMap 中存储的是一一映射的 KV 键值对,并提供了平均复杂度为 O(1) 的查询方法,当我们希望通过一个 Key 去查询值时,该类型非常有用。Rust 中哈希类型(哈希映射)为 HashMap<K,V>,在其它语言中,也有类似的数据结构,例如 hash map,map,object,hash table,字典等等。
创建 HashMap
使用 new 创建
1 | use std::collections::HashMap; |
使用迭代器和 collect 方法创建
1 | use std::collections::HashMap; |
先将 Vec 转为迭代器,接着通过 collect 方法,将迭代器中的元素收集后,转成 HashMap
1 | use std::collections::HashMap; |
所有权转移
HashMap 的所有权规则与其它 Rust 类型没有区别:
- 若类型实现 Copy 特征,该类型会被复制进 HashMap,因此无所谓所有权
- 若没实现 Copy 特征,所有权将被转移给 HashMap 中
1
2
3
4
5
6
7
8
9
10
11
12
13use std::collections::HashMap;
fn main() {
let name = String::from("Sunface");
let age = 18;
let mut handsome_boys = HashMap::new();
handsome_boys.insert(&name, age);
println!("因为过于无耻,{:?}已经被除名", handsome_boys);
println!("还有,他的真实年龄远远不止{}岁", age);
}如果你使用引用类型放入 HashMap 中,请确保该引用的生命周期至少与 HashMap 的生命周期一致。
查询
HashMap 通过 get 方法获取元素,如:
1 | use std::collections::HashMap; |
注意:
- get 方法返回一个 Option<&i32> 类型:当查询不到时,会返回一个 None,查询到时返回 Some(&i32)
- &i32 是对 HashMap 中值的借用,如果不使用借用,可能会发生所有权的转移
更新
HashMap 的更新存在多种情况
1 | fn main() { |