
Rust 从 0 到 1(所有权和借用,复合类型)
Rust 从 0 到 1 学习记录(二)
所有权和借用
在以往,内存安全几乎都是通过 GC 的方式实现,但是 GC 会引来性能、内存占用以及 Stop the world 等问题,在高性能场景和系统编程上是不可接受的,因此 Rust 采用了与众不同的方式:所有权系统。
在程序运行时,都需要和计算机内存打交道,如何申请,如何释放不用的空间。在计算机语言不断演变的过程中,出现了三种流派:
- 垃圾回收机制(GC),在程序运行的过程中不断的寻找不再使用的内存,如:Go,Python,Java
- 手动管理内存的分配和释放:在程序中,通过函数调用的方式来申请和释放内存,如:C++
- 通过所有权来管理内存,编译器在编译时会根据一系列规则检查
Rust 选了所有权来管理内存,这种检查在编译期就完成了,对运行的程序不会造成任何性能的损失。
栈与堆
栈
栈中的所有数据都必须占用已知且固定大小的内存空间。栈中的数据遵循先进后出的原则,增加数据叫进栈,移除数据叫出栈。
堆
与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。堆是一种缺乏组织的数据结构,因此可能带来隐藏的安全问题。
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的指针, 该过程被称为在堆上分配内存,有时简称为 “分配”(allocating)。
所有权原则
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
变量作用域
变量绑定有一个作用域,它被限定只在一个代码块中生存, 代码块是被一个 {} 包围的语句集合。如:
1 | { // s 在这里无效,它尚未声明 |
Rust 为我们提供动态字符串类型: String, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
转移所有权
1 | let x = 5; |
在这段代码中并没有发生权限的转移,因为:
整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过自动拷贝的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
因此这里这段代码的意义是:首先将 5 绑定到变量 x ,接着拷贝 x 的值并赋值给 y ,最终 x 和 y 都等于 5。整个过程中都是值拷贝的方式(都在栈中),因此并不需要转移所有权。
1 | let s1 = String::from("hello"); |
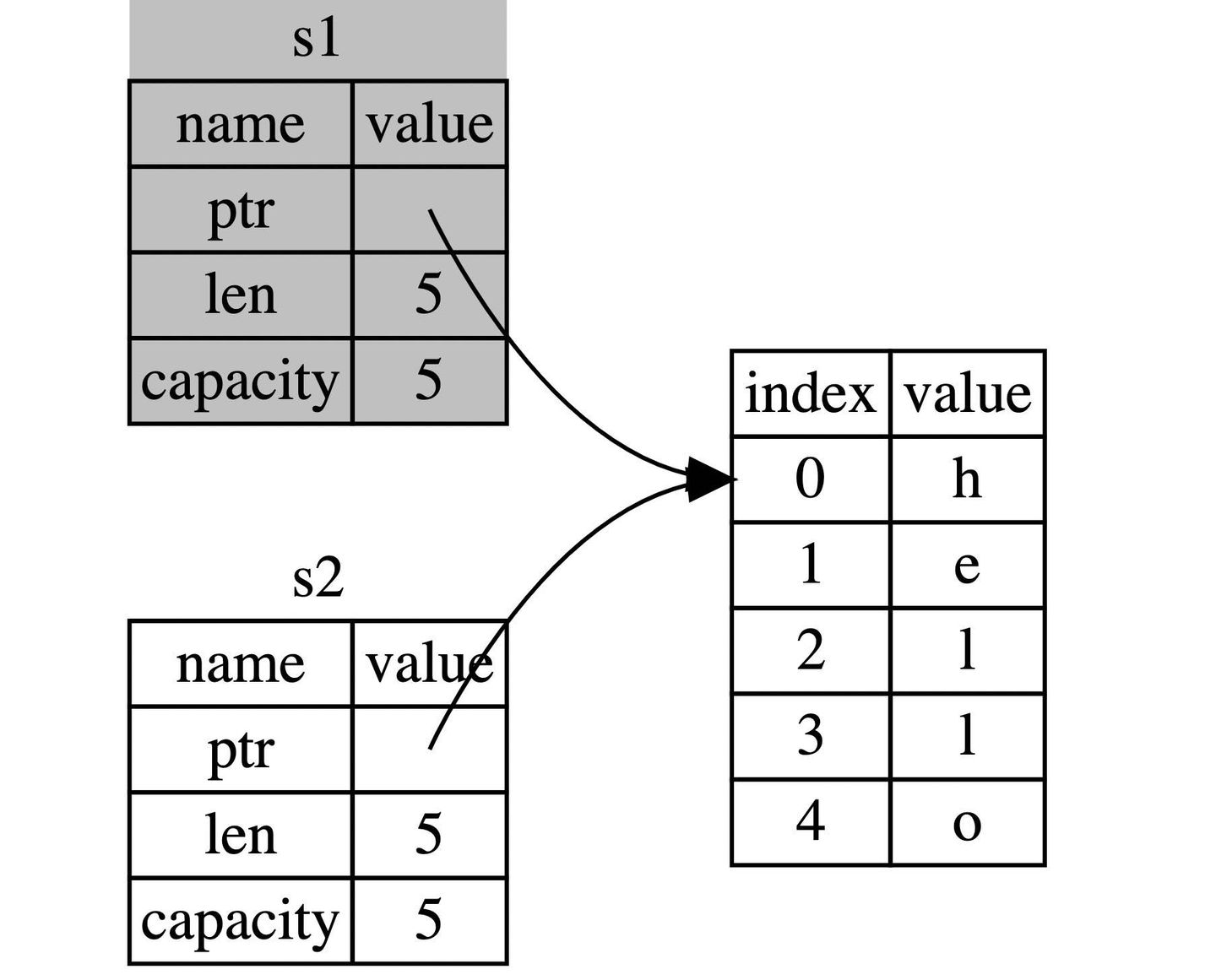
String 类型是一个复杂类型,由存储在栈中的堆指针、字符串长度、字符串容量共同组成,其中堆指针是最重要的,它指向了真实存储字符串内容的堆内存。
因此在这里并不存在值拷贝。假如一个值可以有两个所有者?比如上面的 s1 和 s2 都指向了 “hello,world!”,由于 Rust 会在变量离开其作用域时 drop掉内容,那么 s1 和 s2 离开作用域时,Rust 会调用两次 drop 来释放掉同一段内容,这就回导致一个 二次释放 的错误。因此 Rust 为了避免这种错误,规定一个值只能有一个所有者。
在 Rust 中这种拷贝指针,长度和容量而不拷贝数据,且又使第一个变量无效的操作成为为 move。这个图能很好的解释 move 操作。
再来看一段代码
1 | let s1 = String::from("hello"); |
这代码与之前的代码区别在于:s1 持有 “hello,world!” 的所有权,而 s2 只是引用了 s1 的值,并没有持有 “hello,world!” 的所有值。
克隆
Rust 不会自动创建数据的深拷贝,因此任何自动复制都不是深拷贝。
看代码:
1 | let s1 = String::from("hello"); |
这段代码能够运行,说明 s2 复制了 s1 的数据。
拷贝
Rust 中的浅拷贝只发生在栈上。对于 Rust 来说基本类型在编译时是已知大小的,这些类型都会被存储在栈上,所以没有必要将变量设置为无效。看下面的代码:
1 | let x = 5; |
Rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型。如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用,也就是赋值的过程即是拷贝的过程。 任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。
如:
- 所有整数类型,比如 u32
- 布尔类型,bool,它的值是 true 和 false
- 所有浮点数类型,比如 f64
- 字符类型,char
- 元组,当且仅当其包含的类型也都是 Copy 的时候。比如,(i32, i32) 是 Copy 的,但 (i32, String) 就不是
- 不可变引用 &T
函数传值和返回
将值传递给函数,一样会发生 移动 或者 复制,如下面的代码所示:
1 | fn main() { |
引用和借用
在 Rust 中是借用(Borrowing)这一概念来实现使用某个变量的指针或者引用,获取变量的引用,称之为借用。
1 | fn main() { |
变量 x 存放了一个 i32 值 5。y 是 x 的一个引用。可以断言 x 等于 5。然而,如果希望对 y 的值做出断言,必须使用 *y 来解出引用所指向的值(也就是解引用)。一旦解引用了 y,就可以访问 y 所指向的整型值并可以与 5 做比较。
不可变引用
首先来看代码
1 | fn main() { |
在这里, & 符号即是引用,它们允许你使用值,但是不获取所有权。通过 &s1 语法,我们创建了一个指向 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域后,其指向的值也不会被丢弃。
可变引用
在 Rust 中变量默认不可变,因此引用指向的值也是默认不可变的。那么如果修改引用的值呢?看代码:
1 | fn main() { |
首先,声明 s 是可变类型,其次创建一个可变的引用 &mut s 和接受可变引用参数 some_string: &mut String 的函数。
- 可变引用同时只能存在一个
可变引用并不是想用就用的,其限制为:同一作用域,特定数据只能有一个可变引用,例如下面的代码在编译时就会报错:因为在同一作用域类,变量 s 存在两个可变引用。但是可以手动指定作用域,如:1
2
3
4
5
6let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);1
2
3
4
5
6
7
8let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 在这里离开了作用域,所以我们完全可以创建一个新的引用
let r2 = &mut s; - 可变引用与不可变引用不能同时存在
1 | let mut s = String::from("hello"); |
错误原因是不可变引用和可变引用同时存在。
悬垂引用
悬垂引用也叫做悬垂指针,意思为指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能不存在任何值或已被其它变量重新使用。在 Rust 中编译器可以确保引用永远也不会变成悬垂状态:当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
比如下面的代码,就是悬垂指针:
1 | fn main() { |
复合类型
所谓复合类型,就是有其他类型组合而成的,如:struct 和 enum。
切片
切片并不是 Rust 中独有的概念,如 Go 语言中就非常流行。它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对 String 类型中某一部分的引用。如:
1 | let s = String::from("hello world"); |
由此我们可知创建切片的语法:[start..end],其中 start 是切片的第一个元素的索引位置,而 end 是最后一个元素的索引位置。这是一个 左闭右开 的区间。
使用 .. range 序列语法时,从 0 开始,可以是用如下两种方式:
1 | let s = String::from("hello"); |
包含最后一个元素,可使用:
1 | let s = String::from("hello"); |
截取完整的 String 切片:
1 | let s = String::from("hello"); |
值得注意的是:切片的索引必须落在字符之间的边界位置。也就是 UTF-8 字符的边界,如:
1 | let s = "你好世界!"; |
这里只截取了字符串的前两个字节,由于汉字占三个字节,因此没有落在边界处,截取的字符不完整,则程序的崩溃退出。
字符串切片的类型标识是 &str,数组切片的类型是 &[i32]。
字符串字面量是切片
如:
1 | let s = "Hello, world!"; |
字符串
所谓字符串是由字符组成的连续集合,在 Rust 中只有一种字符串类型 str,其引用类型是 &str。当然也还有其他的字符串类型,如标准库中的 String。
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
字符串常用的功能
String 与 &str 的转换
首先是 &str -> String:1
2String::from("hello,world")
"hello,world".to_string()而 String -> &str 直接取引用就好:
1
2
3
4let s = String::from("hello,world!");
let s1 = &s;
let s2 = &s[..];
let s3 = s.as_str();字符串索引
在 Rust 中是不允许索引字符串(String)的,由于 Rust 是采用 UTF-8 编码,因此对于不同语言来说索引是有差异的,如:1
let hello = String::from("Hola");
在 Hola 是 4 个字节的长度,而对于:
1
let hello = String::from("打工人");
则是 9 个字节的长度。
字符串切片
Rust 中的切片的索引是通过字节进行的,因此在对字符串进行切片时需要保证索引的字节落在字符的边界上,否则就会报错。操作字符串
- 追加 (Push),有两种方式:
push()方法追加字符 char 和push_str()方法追加字符串字面量 - 插入 (Insert),有两种范式: insert() 方法插入单个字符 char 和 insert_str() 方法插入字符串字面量,需要传递插入位置的索引
- 替换 (Replace)
- replace,适用于 String 和 &str 类型,接受两个参数,一个是需要替换的字符,另外一个是新字符
- replacen,适用于 String 和 &str 类型,接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数并返回一个新字符串
- replace_range,适用于 String 类型,接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串,该方法在原字符串操作,需要 mut 关键字修饰
- 删除 (Delete),有四个方法:
pop(),remove(),truncate(),clear()- pop —— 删除并返回字符串的最后一个字符
- remove —— 删除并返回字符串中指定位置的字符
- truncate —— 删除字符串中从指定位置开始到结尾的全部字符
- clear —— 清空字符串
- 连接 (Concatenate),使用 + 或者 += 连接字符串,要求右边的参数必须是字符串的切片引用类型,还可以使用 format! 连接字符串
转义
可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符,如:
1 | let byte_escape = "I'm writing \x52\x75\x73\x74!"; |
元组
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的。
创建一个元组
1 | let tup: (i32, f64, u8) = (500, 6.4, 1); |
可以使用匹配模式和 . 操作符获取元素。如:
1 | // 匹配模式结构 |
元组在函数返回值场景比较常用,如:
1 | fn main(){ |
结构体
结构体是由多种类型组合而成,结构体可以为内部的每个字段起一个名称。首先来看如何定义一个结构体:
1 | struct struct_name { |
如新建一个用户结构体:
1 | struct User { |
该结构体名称是 User,拥有 4 个字段,且每个字段都有对应的字段名及类型声明,例如 name 代表了用户名,是一个可变的 String 类型。接下来生成结构体的实例:
1 | let user1 = User{ |
注意:
- 初始化实例时,每个字段都需要进行初始化
- 顺序不重要
结构体同样可以使用 . 访问内部的字段,如:
1
2
3
4
5
6
7 let mut user1 = User{
name: String::from("wh0am1i"),
age: 18,
email: String::from("123@qq.com"),
active: true,
}
user1.email = String::from("456@qq.com");
要修改结构体字段的值,需要声明结构体是可变的即:使用 mut 关键字进行修饰,Rust 不支持将结构体的某个字段设置为可变的
在正常的开发过程中,创建一个结构体我们会使用一个构造函数来进行构造,如:
1 | fn build_user(name: String, email: String, age: i32) -> { |
这样的语法略显啰嗦,好在 Rust 提供了缩略的写法:当函数参数和结构体字段同名时,可省略。如:
1 | fn build_user(name: String, email: String, age: i32) -> { |
还有一种情况是我们经常遇到的:根据已有的结构体实例,创建新的结构体实例,如:根据 user1 创建 user2
1 | let user2 = User{ |
Rust 同样为我们提供了简便的方法,如:
1 | let user2 = User { |
.. 语法表明我们没有显式声明的字段,全部从 user1 获取。注意:..user1 必须在结构体的尾部使用。
在上面代码中,user1 的部分字段所有权被转移到 user2 中:username 字段发生了所有权转移,作为结果,user1 无法再被使用。但不代表 user1 内部的其他字段不能被继续使用,如:
1 | let user1 = User{ |
实现了 Copy 特征的类型无需所有权转移,可以直接在赋值时进行 数据拷贝,其中 bool 和 i32 类型就实现了 Copy 特征,因此 active 和 age 字段在赋值给 user2 时,仅仅发生了拷贝,而不是所有权转移。
元组结构体
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
1 | struct Color(i32, i32, i32); |
单元结构体
单元结构体和单元类型相似,都是没有任何字段和属性。如:
1 | struct AlwaysEqual; |
结构体打印
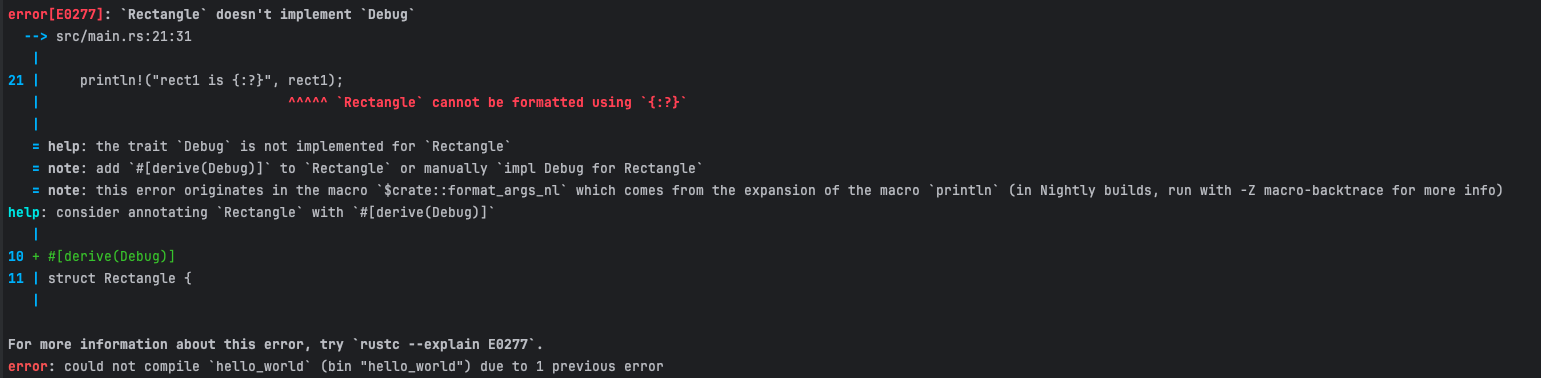
在正常情况下,没有办法直接打印结构体,如:
1 | struct Rectangle { |
直接运行会出现一下报错
Rust 提示我们需要实现 Debug 特征,有两种方式可以实现:
- 手动实现
- 使用 derive 派生
而派生简单许多,因此我们只需要加上 #[derive(Debug)]即可。
枚举
枚举(enum 或 enumeration)允许你通过列举可能的成员来定义一个枚举类型。如性别:
1 | #[derive(Debug)] |
性别就两种,男性和女性(这里不谈论其他的),因此呢: 枚举类型是一个类型,它会包含所有可能的枚举成员, 而枚举值是该类型中的具体某个成员的实例。
我们可以通过 :: 来访问 Gender 下的具体成员,如:
1 | let human1 = Gender::Male; |
在实际中,我们往往需要将数据信息与枚举值关联起来,那么该怎么实现呢?看代码:
1 | #[derive(Debug)] |
运行结果:

使用 Option 枚举处理空值
在其它编程语言中,往往都有一个 null 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 null 进行操作时,例如调用一个方法,就会直接抛出null 异常,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 null 空值。在 Rust 中使用 Option 枚举变量来表述这种结果。
Option 枚举包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None,定义如下:
1 | enum Option<T> { |
其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T。Option 枚举经常用在函数中的返回值,它可以表示有返回值,也可以用于表示没有返回值。如果有返回值。可以使用返回 Some(data),如果函数没有返回值,可以返回 None。如:
1 | fn getDiscount(price: i32) -> Option<bool> { |
数组
在 Rust 中,最常用的数组有两种,第一种是速度很快但是长度固定的 array,第二种是可动态增长的但是有性能损耗的 Vector,在 Rust 中,我们称 array 为数组,Vector 为向量。
数组的具体定义很简单:将多个类型相同的元素依次组合在一起,就是一个数组。
数组三要素:
- 长度固定
- 元素必须有相同的类型
- 依次线性排列
如何创建一个数组:
1 | fn main() { |
声明重复某个值的数组: let a = [3; 5];
由于数组是连续存放元素的,因此我们可以使用索引的方式来访问元素,如:
1 | fn main() { |
注意:数组的索引下标是从 0 开始的
我们在访问数组元素时越界了,Rust 会在编译的过程中提示我们:
index out of bounds,如果数组的元素为非基础元素,同样会提示我们。
数组也是可以切片的,如:
1 | let a: [i32; 5] = [1, 2, 3, 4, 5]; |
上面的数组切片 slice 的类型是&[i32],与之对比,数组的类型是[i32;5],简单总结下切片的特点:
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,&str字符串切片也同理